





HTTP request tunnelling
Many of the request smuggling attacks we've covered are only possible because the same connection between the front-end and back-end handles multiple requests. Although some servers will reuse the connection for any requests, others have stricter policies.
For example, some servers only allow requests originating from the same IP address or the same client to reuse the connection. Others won't reuse the connection at all, which limits what you can achieve through classic request smuggling as you have no obvious way to influence other users' traffic.

Although you can't poison the socket to interfere with other users' requests, you can still send a single request that will elicit two responses from the back-end. This potentially enables you to hide a request and its matching response from the front-end altogether.
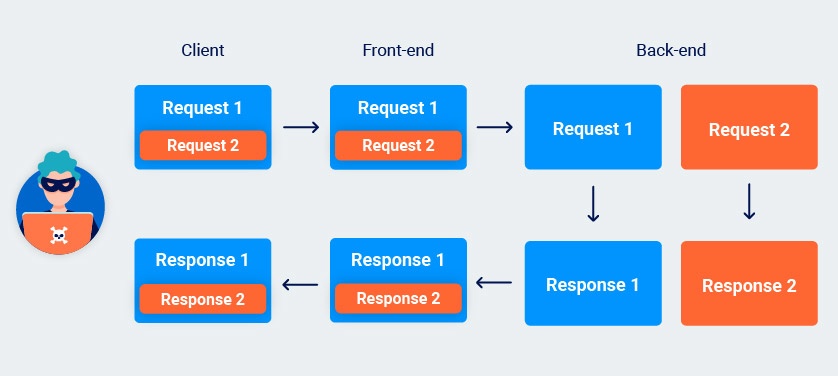
You can use this technique to bypass front-end security measures that may otherwise prevent you from sending certain requests. In fact, even some mechanisms designed specifically to prevent request smuggling attacks fail to stop request tunnelling.
Tunneling requests to the back-end in this way offers a more limited form of request smuggling, but it can still lead to high-severity exploits in the right hands.
Request tunnelling with HTTP/2
Request tunnelling is possible with both HTTP/1 and HTTP/2 but is considerably more difficult to detect in HTTP/1-only environments. Due to the way persistent (keep-alive) connections work in HTTP/1, even if you do receive two responses, this doesn't necessarily confirm that the request was successfully smuggled.
In HTTP/2 on the other hand, each "stream" should only ever contain a single request and response. If you receive an HTTP/2 response with what appears to be an HTTP/1 response in the body, you can be confident that you've successfully tunneled a second request.
Leaking internal headers via HTTP/2 request tunnelling
When request tunnelling is your only option, you won't be able to leak internal headers using the technique we covered in one of our earlier labs, but HTTP/2 downgrading enables an alternative solution.
You can potentially trick the front-end into appending the internal headers inside what will become a body parameter on the back-end. Let's say we send a request that looks something like this:
| :method | POST |
| :path | /comment |
| :authority | vulnerable-website.com |
| content-type | application/x-www-form-urlencoded |
| foo | bar\r\n Content-Length: 200\r\n \r\n comment= |
| x=1 | |
In this case, both the front-end and back-end agree that there is only one request. What's interesting is that they can be made to disagree on where the headers end.
The front-end sees everything we've injected as part of a header, so adds any new headers after the trailing comment= string. On the other hand, the back-end sees the \r\n\r\n sequence and thinks this is the end of the headers. The comment= string, along with the internal headers, are treated as part of the body. The result is a comment parameter with the internal headers as its value.
POST /comment HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 200
comment=X-Internal-Header: secretContent-Length: 3
x=1Blind request tunnelling
Some front-end servers read in all the data they receive from the back-end. This means that if you successfully tunnel a request, they will potentially forward both responses to the client, with the response to the tunnelled request nested inside the body of the main response.
Other front-end servers only read in the number of bytes specified in the Content-Length header of the response, so only the first response is forwarded to the client. This results in a blind request tunnelling vulnerability because you won't be able to see the response to your tunnelled request.
Non-blind request tunnelling using HEAD
Blind request tunnelling can be tricky to exploit, but you can occasionally make these vulnerabilities non-blind by using HEAD requests.
Responses to HEAD requests often contain a content-length header even though they don't have a body of their own. This normally refers to the length of the resource that would be returned by a GET request to the same endpoint. Some front-end servers fail to account for this and attempt to read in the number of bytes specified in the header regardless. If you successfully tunnel a request past a front-end server that does this, this behavior may cause it to over-read the response from the back-end. As a result, the response you receive may contain bytes from the start of the response to your tunnelled request.
Request
| :method | HEAD |
| :path | /example |
| :authority | vulnerable-website.com |
| foo | bar\r\n \r\n GET /tunnelled HTTP/1.1\r\n Host: vulnerable-website.com\r\n X: x |
Response
| :status | 200 |
| content-type | text/html |
| content-length | 131 |
HTTP/1.1 200 OK Content-Type: text/html Content-Length: 4286 <!DOCTYPE html> <h1>Tunnelled</h1> <p>This is a tunnelled respo |
|
As you're effectively mixing the content-length header from one response with the body of another, using this technique successfully is a bit of a balancing act.
If the endpoint to which you send your HEAD request returns a resource that is shorter than the tunnelled response you're trying to read, it may be truncated before you can see anything interesting, as in the example above. On the other hand, if the returned content-length is longer than the response to your tunnelled request, you will likely encounter a timeout as the front-end server is left waiting for additional bytes to arrive from the back-end.
Fortunately, with a bit of trial and error, you can often overcome these issues using one of the following solutions:
-
Point your
HEADrequest to a different endpoint that returns a longer or shorter resource as required. -
If the resource is too short, use a reflected input in the main
HEADrequest to inject arbitrary padding characters. Even though you won't actually see your input being reflected, the returnedcontent-lengthwill still increase accordingly. -
If the resource is too long, use a reflected input in the tunnelled request to inject arbitrary characters so that the length of the tunnelled response matches or exceeds the length of the expected content.
Web cache poisoning via HTTP/2 request tunnelling
Even though request tunnelling is generally more limited than classic request smuggling, you can sometimes still construct high-severity attacks. For example, you may be able to combine the request tunnelling techniques we've looked at so far for an extra-powerful form of web cache poisoning.
With non-blind request tunnelling, you can effectively mix and match the headers from one response with the body of another. If the response in the body reflects unencoded user input, you may be able to leverage this behavior for reflected XSS in contexts where the browser would not normally execute the code.
For example, the following response contains unencoded, attacker-controllable input:
HTTP/1.1 200 OK
Content-Type: application/json
{ "name" : "test<script>alert(1)</script>" }
[etc.]
By itself, this is relatively harmless. The Content-Type means that this payload will simply be interpreted as JSON by the browser. But consider what would happen if you tunnel the request to the back-end instead. This response would appear inside the body of a different response, effectively inheriting its headers, including the content-type.
| :status | 200 |
| content-type | text/html |
| content-length | 174 |
HTTP/1.1 200 OK Content-Type: application/json { "name" : "test<script>alert(1)</script>" } [etc.] |
|
As caching takes place on the front-end, caches can also be tricked into serving these mixed responses to other users.
Register for free to track your learning progress

-
Practise exploiting vulnerabilities on realistic targets.
-
Record your progression from Apprentice to Expert.
-
See where you rank in our Hall of Fame.
Already got an account? Login here